Introduction
AI-powered applications have become a core part of modern digital experiences. From chat-bots and virtual assistants to recommendation engines and image generation tools, users expect AI systems to deliver accurate responses quickly. Behind the scenes, however, AI engineers face a constant challenge: balancing throughput and latency.
These two-performance metrics are closely connected, and improving one can often negatively affect the other. Understanding this trade-off is essential for designing efficient AI serving systems.
Why Performance Metrics Matter in AI Serving
When an AI model is deployed in production, its success is measured not only by accuracy but also by how efficiently it serves requests. A highly accurate model that responds too slowly may frustrate users, while a system optimized only for speed may struggle to handle large volumes of traffic.
This is where throughput and latency become critical indicators of performance.
What Is Throughput?
Throughput refers to the number of requests an AI system can process within a specific period. It measures the overall capacity of the infrastructure.
For example, an AI service that can handle 1,000 requests per second has higher throughput than one that can only process 200 requests per second. The higher the throughput, the more users a system can support simultaneously.
What Is Latency?
Latency measures how long it takes for a user to receive a response after submitting a request.
In AI systems, latency includes:
- Request transmission time
- Queue waiting time
- Model inference time
- Response delivery time
Users generally notice latency far more than throughput. A chat-bot that takes several seconds to respond may feel slow, even if the system is processing thousands of other requests efficiently.
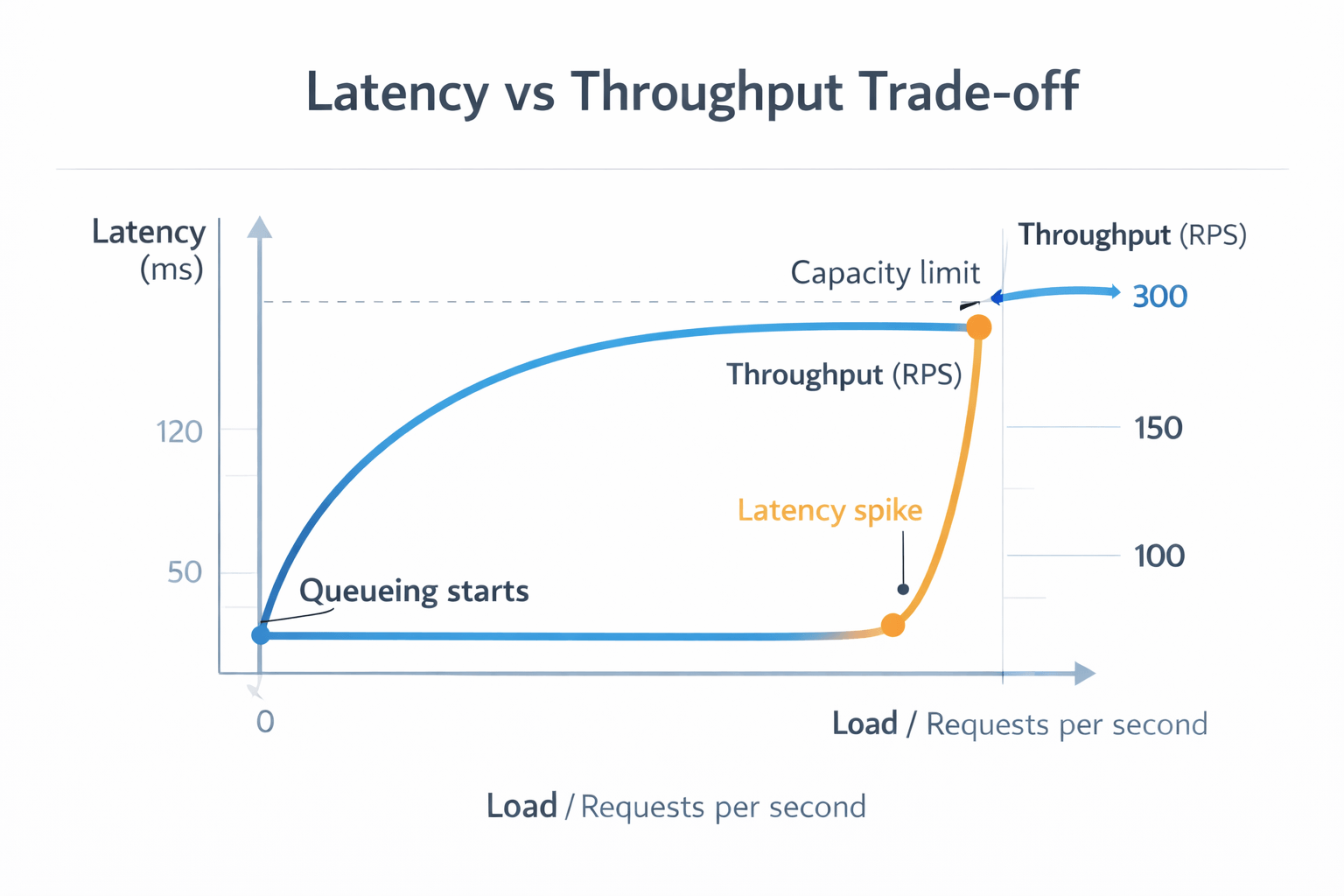
Why Throughput and Latency Compete
The conflict between throughput and latency largely stems from resource utilization. To maximize GPU efficiency, AI serving platforms often group multiple requests together using batching. Instead of processing one request at a time, the system processes many requests simultaneously.
This approach offers significant benefits:
- Better GPU utilization
- Reduced processing cost per request
- Higher overall throughput
- Improved infrastructure efficiency
However, requests may need to wait until enough requests arrive to form a batch. This waiting period increases latency. As batch sizes grow, throughput improves, but response times often become longer.
A Simple Example
Imagine a restaurant kitchen.
If the chef prepares one meal immediately after receiving an order, customers receive food quickly. This resembles low-latency AI serving.
Alternatively, the chef may wait until several orders arrive and cook them together. This improves efficiency and allows more meals to be prepared overall, similar to high-throughput AI serving.
The downside is that some customers must wait longer before cooking begins. AI systems face a similar decision when managing inference workloads.
How Modern AI Platforms Balance the Trade-Off
Leading AI serving frameworks use several techniques to balance throughput and latency:
1. Dynamic Batching
The system automatically adjusts batch sizes based on traffic levels, helping maintain responsiveness during low demand while maximizing efficiency during peak periods.
2. Priority Scheduling
Time-sensitive requests receive faster processing than lower-priority tasks.
3. Load Balancing
Traffic is distributed across multiple servers to prevent bottlenecks and reduce delays.
4. Model Optimization
Techniques such as quantization and model compression reduce inference times without requiring additional hardware.
Conclusion
The most successful AI serving architectures understand the needs of their users and optimize accordingly. By carefully balancing throughput and latency, organizations can deliver scalable AI services while maintaining a fast and reliable user experience.